...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
| Table of Contents |
|---|
| Anchor | ||||
|---|---|---|---|---|
|
...
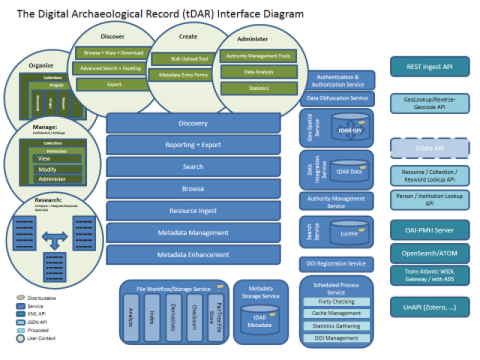
The tDAR data model (bean model) is built around the needs of expressing and managing data about archaeological information and managing administrative information. At the center of the model is the Resource. Although Resource is not an abstract class, it is never explicitly instantiated – due to some functional requirements with Hibernate and Hibernate Search, it cannot be abstract. Resources are split into two categories, those with files, and those without. Projects, resources without files, exist to help with data management for multiple resources. InformationResource objects, resources with files, exist in a number of forms – Document, Dataset, Image, and supporting formats (Coding Sheet, and Ontology). InformationResource beans may be part of a Project. Resources can be managed and organized through ResourceCollection objects and are described via various Keyword Objects. Resources are also related to Creators (People and Institutions) through both rights and other roles.
Figure 1: tDAR Resource Class Hierarchy
Figure 2: tDAR Keyword Class Hierarchy
The inheritance and relationships are managed by JPA 2.0 and hibernate, as well as within the Java Bean Hierarchy. This affordance is likely necessary in the code, but does complicate some of the hibernate interactions. At the center of the data model are a set of interfaces and static classes that centralize and manage
Serialized Data Models
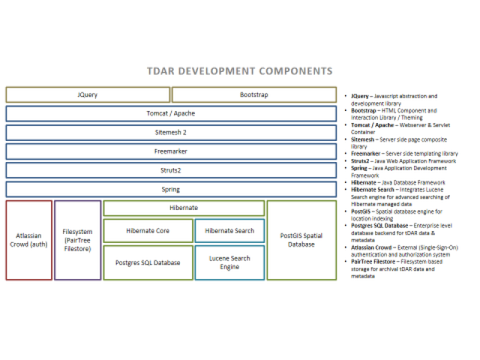
There are effectively three separate serialized data models for tDAR: the SQL database through hibernate, the Lucene indexes through hibernate search, Java objects through Freemarker, and XML and JSON through JAXB (mainly).
These serializations provide both benefits and complexities to tDAR. There is both the challenge of keeping the data in sync across all representations, but also filtering data that may not be appropriate to that context, or that the user does not have the rights to see.
...
tDAR uses XML and JSON for serialization of data to internal and external sources. Originally, tDAR used xStream and Json-lib to manage serialization of data to XML and JSON respectively. Over time, we've removed xStream and replaced it with JAXB, and have moved away from Json-lib in place of Jackson, though more work needs to be done here.
XML Serialization was primarily for internal use and re-use, it facilitated messaging and transfer of data between different parts of the system. XML serialization also allowed for logging of complex objects such as data integration, record serialization for messaging, record serialization into the filestore as an archival representation, and the import API. JSON serialization was mainly for use and re-use of tDAR data by the JavaScript layer of the tDAR software.
Moving forward, there are a number of challenges to approach with XML and JSON serialization. As we move toward pure JAXB serialization of data for both JSON and XML, tDAR must tackle the fact that the different serializations have different data requirements. While the internal record serialization should contain all fields and all values, JSON serialization may want to or need to filter out data such as email addresses or personally identifiable information. XML that may be useful in a full record serialization may not be appropriate for data import (transient values, for example). Another challenge is maintaining the XML schema versioning in line with the data model changes as both need to be revised at the same time, and changes to the schema cause backwards compatibility issues with the XML in the filestore.
One option to tackle some of these issues might be to implement Jackson's serialization profiles for different formats to serialize the same JSON. Similarly, MoXy may be a better JAXB implementation than the default.
Service Layer
Spring & Autowiring
tDAR uses the Spring Integration framework to assist in management of dependencies and services throughout the application. In many case, these dependencies and services are simply academic in their "interchangeability." That is, most of our Dao's and services are pretty implementation specific, though we have swapped a few out over time. Spring mainly allows us to configure new services and existing services quickly and easily. As the application has grown however, one of the challenges is that our services are dependent on other services. Although we've attempted to keep this to a minimum, it does add complexity. A few different solutions have been chosen (1) using getters to access the shared service (e.g. getting the AuthenticationAndAuthorizationService from the ObfuscationService); (2) moving shared components into a new service with no dependencies; and, (3) moving logic into the Dao layer if necessary. As tDAR continues to grow, some of the autowiring logic may need to be reviewed and revisited.
tDAR does have a few "configurable" services that allow it to be extended to different working environments. These are built around external dependencies, specifically authentication and authorization through the "AuthenticationAndAuthorizationService" and DOI generation via the DOIService. These services has multiple Daos to back their features. For DOIs, this is one for EZID and one for ANDS. For authentication and authorization, we utilize a number of DAOs, different methods for connecting to Atlassian's Crowd, LDAP, and a few local "test" setups.
The final use for autowiring is for tracking all implementations of various interfaces. The primary example being the Workflows. This use allows us to make sure that all implemented Tasks, and Workflows are wired in together without having to explicitly manage the instances ourselves.
...
tDAR's file storage and management model is heavily influenced by the California Digital Library's Micro-Services model. Data is stored on the file-system in a pre-determined structure described as a PairTree filestore https://confluence.ucop.edu/display/Curation/PairTree. The filestore maintains archival copies of all of the data and metadata in tDAR. This organization allows us to map any data stored within the Postgres database that supports the application's web interface with the data stored on the file-system, while also partitioning data on the file-system into manageable chunks Technically, the user interface is driven by the Postgres database and a set of Lucene indexes for search and storing data. The resource IDs (document, data set, etc.) are the keys to the Pairtree store. When a resource is saved or modified, the store is updated, keeping data in sync.. Each branch of the filestore is a folder for each record, "rec/" illustrated in Figure 2, below. Data associated with each tDAR record is stored in a structure inspired by the D-Flat https://confluence.ucop.edu/display/Curation/D-flat convention ensuring a consistent organization of the archival record.
| Anchor | ||||
|---|---|---|---|---|
|
| Anchor | ||||
|---|---|---|---|---|
|
/home/tdar/filestore/36/67/45$ tree
— rec/
(1) |-- record.2013-02-12--19-44-32.xml
...
As tDAR's functionality expands, and the number of files and formats is increased, these workflows will need to be improved and increase their flexibility and functionality.
Web Layer – Struts2, Freemarker, JavaScript, CSS, and HTML
Controllers – Struts2
tDAR uses Struts2 to provide support for tDAR's controllers. At the point that it was chosen, struts2 and the convention plugin appeared to provide simplicity to the web layer from both the configuration and data publication modes with less XML configuration and less glue-code, especially with Freemarker being integrated more directly.
We have customized Struts2 in a number of ways, first on the configuration, we've adjusted the default stacks to include additional interceptors, second, we have added layers of security, and third, we've diverged from the defaults Struts2 model in a few ways to help simplify development using a base controller for many shared functions. This controller model has been both helpful and complicated matters in a few places, and in the future we should consider migrating to a more standard struts2 model.
AbstractPersistableController
Figure 3:tDAR AbstractPersistableController Class Hierarchy
The AbstractPersistableController is probably the most complex structure within the tDAR controller infrastructure and attempts to manage and simplify CRUD (Create / Update / Delete / View) actions within tDAR by centralizing most of the logic and flow, and allowing stub methods to be overridden by subsequent controllers to adjust the workflow as needed. The controller breaks actions down into the general following process:
...
The other major controller hierarchy is the SearchResultHandler interface and AbstractLookupController hierarchy. The goal of the abstract class and interface are intended to standardize and centralize how tDAR interacts with both search results and the SearchService. The interface provides standard names for parameters supporting searching including for pagination for the end-user interface. It also allows for a standard interface between search controllers and the search service for managing common parameters there such as the query, results, and sorting among others.
Over time, we've begun to use the SearchParameters and ReservedSearchParameters class to assist in the creation and management of queries within the system as well. These helper classes assist in the generation of Boolean search queries by collecting the objects for us without us manually generating groups of fields. The objects themselves were built out of refactoring the AdvancedSearchController to handle generic Boolean searches, but have also helped with simply simplifying the logic.
Figure 4: AbstractLookupController Hierarchy
Asynchronous Actions
Due to complexity of actions, a number of controllers have asynchronous actions associated with them. A few are interactive, while most are not. These asynchronous actions are associated with long-running tasks such as indexing, re-indexing, and loading or processing of data. Asynchronous data processing is done through two different models depending on the result.
...
On top of the standard interceptor stack for Struts, we've added a few additional custom interceptors to the tDAR stack.

HTTPMethod Interceptor
This interceptor allows us to control which HTTP Methods can be called on a given class or action. This is critical for delete and save actions within tDAR which should always use a POST method for two reasons: (a) because of the complexity of the request exceeding the maximum length for a GET, but also because of how struts2 interacts with the stack here which does not always work properly with a POST. Another logical place for this is on a Login action to ensure that the login is done via POST to ensure that passwords are not included as part of the URL.
...
A large portion of JavaScript code is written by Digital Antiquity and this code serves three main purposes: it serves to implement functionality that is not available from 3rd party code; conversely, we write custom code to extend and generalize 3rd party JavaScript so that it can be used in a tDAR context.
As the use of JavaScript increases, so too does the potential for unwanted side-effects. To mitigate these side-effects we are in the process of minimizing our use of the JavaScript by "namespacing" our locally-developed JavaScript. That is, we expose one global object named "TDAR" and provide access to TDAR-specific properties and functions via this global object. We plan to further modularize TDAR's JavaScript in the coming months.
Organization
- TDAR.common: Common functions and utilities that are utilized on most pages in tDAR, and low-level functionality utilized by the other TDAR components
- TDAR.advancedSearch: functionality related to to the tDAR's "Advanced Search" page.
- TDAR.autocomplete: provides the functionality for "autocomplete" form fields.
- TDAR.contexthelp: enables context-sensitive help pop-ups on various tDAR forms.
- TDAR.datatable: extends the JQuery DataTable plugin and allows it to be more-easily used in conjunction with tDAR-specific data.
- TDAR.fileupload: extends the JQuery File Upload plugin , enables validation rules on the types of files and file names that users may upload to tDAR.
- TDAR.integration: support for TDAR's dataset integration UI.
- TDAR.maps: enables google map support, provides UI that allows users to designate map boundaries for tDAR resources.
- TDAR.pricing: support for TDAR's pricing page UI.
- TDAR.repeatrow: enables support for multi-valued data-entry in tDAR forms.
Concerns & Potential Pitfalls
...
We plan to mitigate the problems above through the use of automatic module loading solutions such as AMD or through the use of Common.js pre-processing solutions.
Major 3rd-Part JavaScript Components
...